How to Organize DevLake Projects
This guide provides a step-by-step approach to organizing projects in DevLake, enabling you to measure DORA metrics according to your specific use cases.
1. What is a DevLake project?
On a high level, a DevLake project can be viewed as a real-world project or product line. It represents a specific initiative or endeavor within the software development domain.
On a lower level, a DevLake project is a way of organizing and grouping data from different domains. DevLake uses various data scopes, such as repos, boards, cicd_scopes, and cq_projects as the 'container' to associate different types of data to a specific project. See more on this doc.
2. Why is it important to organize projects?
This is crucial due to the fact that DevLake measures DORA metrics at the project level. Each project is associated with specific key entities, such as 'pull requests', 'deployments', and 'incidents', which are used to calculate the corresponding DORA metrics. Therefore, proper project organization ensures accurate and meaningful DORA metric calculations for effective analysis and evaluation.
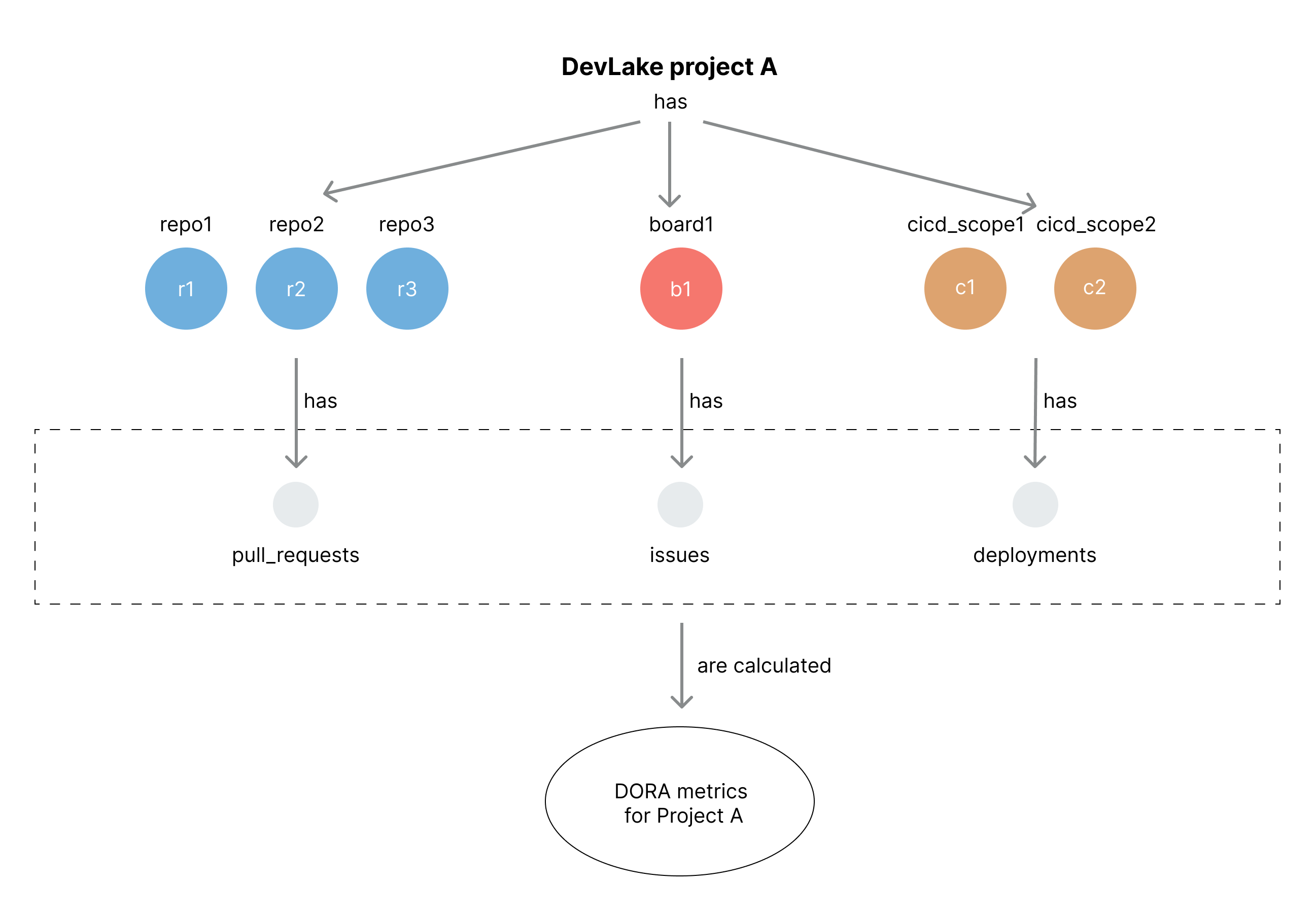
How are four DORA metrics calculated from 'pull requests', 'deployments', and 'incidents'?
- Deployment Frequency: How often does a project
deploys?- Lead Time for Changes: How fast are the
pull requestsdelivered?- Change Failure Rate: How many
deploymentslead toincidents?- Median Time to Restore: How fast are
incidentssolved?
3. Challenges in project organization
There are several challenges associated with organizing projects in DevLake due to different development practices within teams. Some of these challenges include:
- Managing multiple Git repos, issue boards, and CI/CD pipelines within a project.
- Having a Git repo, issue board, or CI/CD pipeline associated with multiple projects, such as in the case of mono-repos or boards used to track incidents from user feedback.
- Managing multiple projects within a team and the need to measure DORA metrics at the team level.
- Projects contributed by multiple teams, with each team requiring the ability to measure their own DORA metrics.
This document serves as a guide to address these challenges and provide assistance in effectively dealing with these diverse development practices.
4. General advice
4.1. Determining the number of DevLake projects
It is advisable to create DevLake projects that align with the number of real-life projects you have.
For example, if you have a team (Team A) responsible for managing multiple projects, it is recommended to create separate DevLake projects for each individual project instead of creating a single project named 'Team A'. This approach allows for better organization and tracking of metrics specific to each project.
4.2 Principles of organizing projects
When organizing projects in DevLake, it is important to associate all relevant data scopes, such as repos, issue boards, and CI/CD scopes, with the corresponding DevLake project based on real-life practices.
In situations where a repo or board is shared by multiple projects in real life, it is recommended to include them in all of these projects within DevLake. This is because DevLake cannot differentiate which commits or issues belong to specific projects. Rather than excluding shared resources from DORA measurements, it is advisable to consider them in all relevant projects.
4.3 Measuring DORA at the team level
To clarify the concepts, let's define three terms:
- Project: Refers to a real-world project or product line, such as Apache DevLake or Apache Spark. It focuses on the work to be done.
- Team: Represents a department, such as the 'product team' or 'engineering team'. It focuses on the people and their roles. Note that people within the same team may not always work on the same projects.
- Project Team: Comprises individuals working on a specific project.
DevLake does support measuring DORA metrics at the project-team level, which is essentially the same as measuring at the project level. However, it is important to note that DevLake does not recommend measuring DORA metrics at the team level. Despite the existence of the 'DORA by team' dashboard contributed by the community. Doing so may introduce inaccuracies and dilute the significance of measuring DORA metrics from the outset.
5. Use Cases
This section demonstrates real-life practices and how they get reflected in DevLake.
Disclaimer: To keep this guide shorter, some technical details are only mentioned in Use Case 1, so if you read this page for the first time, make sure to go through them in order.
Note: If you use webhooks, check the quick note about them below.
5.1. Use Case 1: Apache Projects
Apache Software Foundation (ASF) has and is developing many projects.
To take an example we will analyze 2 projects: DevLake and Spark.
Both are independent of each other. Assume that ASF wants to check the health of the development
and maintenance of these projects with DORA.
DevLake manages 3 repos: incubator-devlake,
incubator-devlake-website,
and incubator-devlake-helm-chart.
There are many repos related to Spark in one way or another. To keep it simple,
we will also pick 3 repos: spark,
spark-website, and incubator-livy.
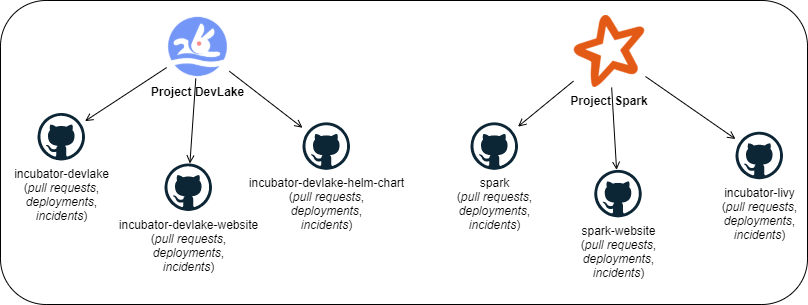
Both projects use GitHub for storing code (including pull requests), deployments on GitHub Actions, and incidents.
Note: To avoid confusion between DevLake as a project in this use case and DevLake as a platform,
we will use complete names i.e. project DevLake and platform DevLake respectively.
5.1.1. Organizing Projects
First, create two projects on the DevLake platform, one for DevLake and one for Spark. These will represent real-world projects.
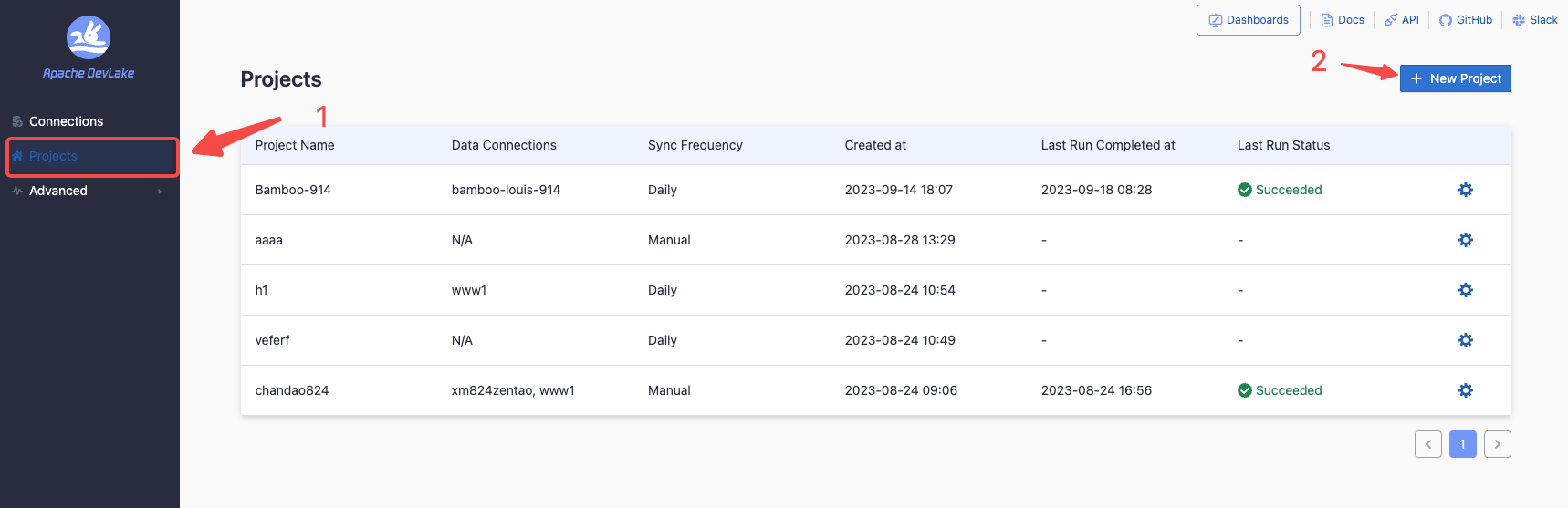
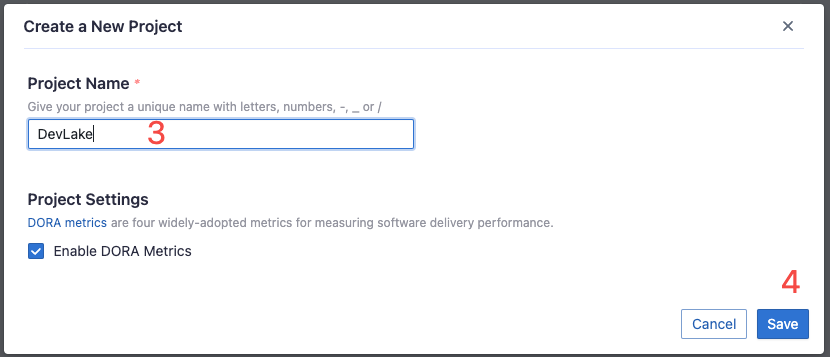
Once these are created, the connections created in the following steps will be bound to them.
5.1.2. Creating Connections
Since all is on GitHub in this case, we can use just 1 connection with the following properties:
- it includes all the project's
repos - its scope includes everything we work with (i.e.
pull requests,deployments, andincidents)
If you store incidents on Jira, for example, you will need to create a separate connection just for them.
The same applies to deployments, a separate connection is needed in case they are stored in Jenkins (or any other host for deployments).
5.1.3. Configuring Connections
This part is described in GitHub connection configuration. Please check the configuration guide for configuring other data sources.
5.1.4. Using Connections
At this point, we have projects and connections created on the platform DevLake. It is time to bind those connections to the projects. To do so, follow the steps described in the Tutorial.
5.1.5. Resulting Metrics
To know if the data of a project is successfully collected to your DORA Dashboard:
If everything goes well, you should see all the 4 charts. If something is wrong, and you are puzzled as to why, check out the Debugging Dora Issue Metrics page.
5.1.6. How can I observe metrics by project?
In the same DORA dashboard check out this menu point:
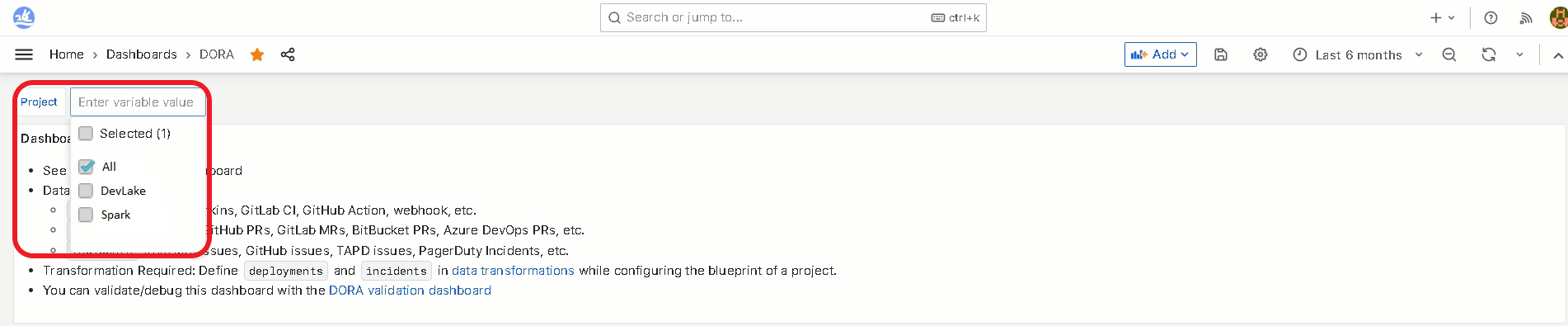
The metrics should change when you select or deselect projects, representing the projects you selected.
5.2. Use Case 2: Multiple Teams with Distinct Projects
Consider a scenario where a company operates with several teams, each managing one or more projects. For illustration, we will explore two such teams: the Payments team and the Internal Tools team. Here's a simplified representation of this scenario:
Quick Overview:
- The Payments team works on a single project: “payments”.
- The Internal Tools team manages two projects: “it-legacy” and “it-new”.
- Both teams use different sets of tools and boards.
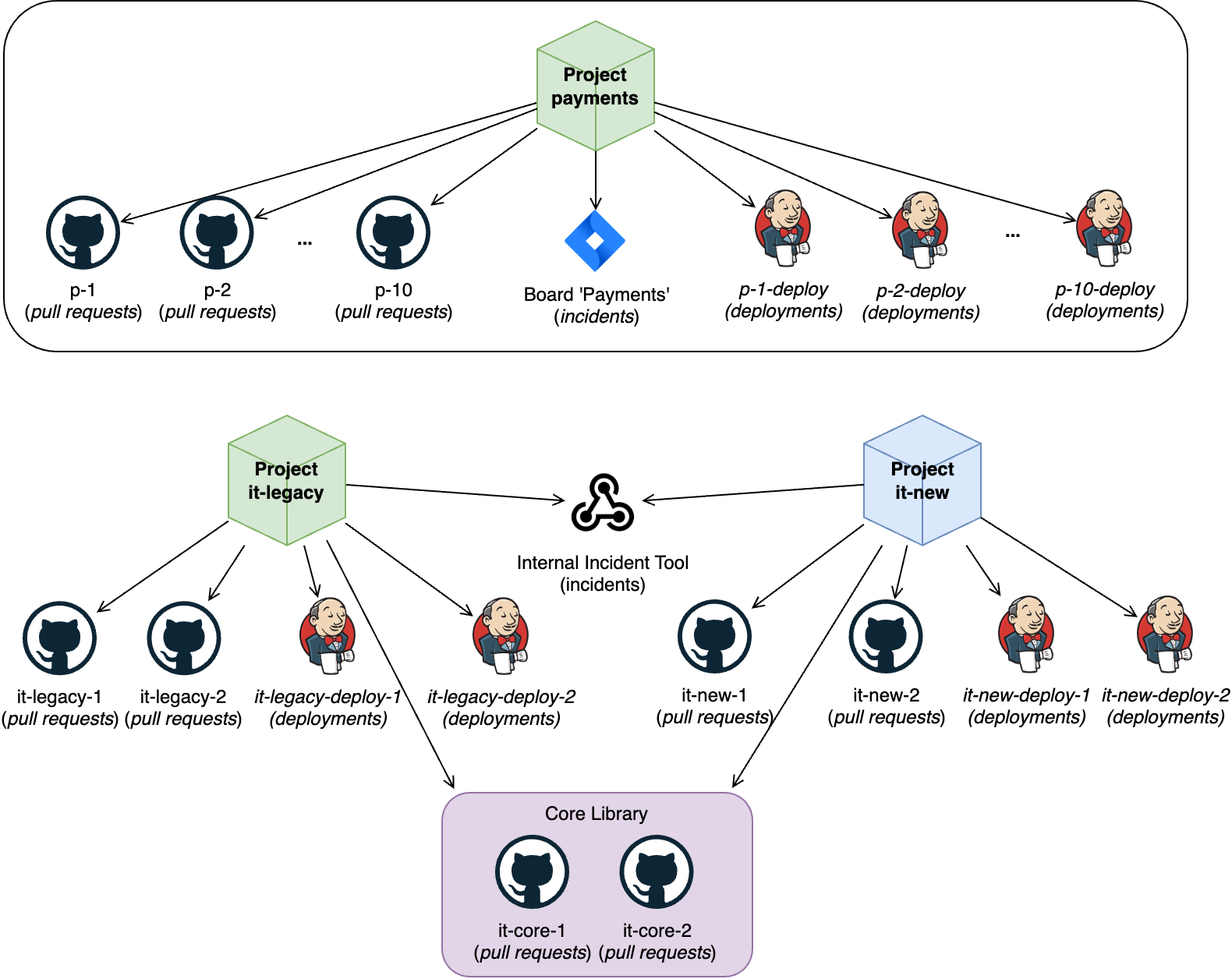
Step-by-Step Simplification:
- Define the Teams and Projects:
- Payments Team:
- One project: "payments".
- Internal Tools Team:
- Two projects: "it-legacy" and "it-new".
- Payments Team:
- Understand the Tools:
- Assume both teams utilize GitHub for
reposand Jenkins for CI/CD. - The Payments team uses Jira boards.
- The Internal Tools team uses webhooks for reporting incidents.
- Assume both teams utilize GitHub for
5.2.1. Organizing Projects
DORA is effective for observing the impacts of methodology changes within a team.
From DORA’s standpoint, the concept of distinct teams is not recognized; only projects exist.
Adding a team concept introduces unnecessary complexity without providing any substantial benefit.
In DevLake, we create three projects: payments, it-legacy, and it-new.
It is crucial to maintain atomic projects, representing the smallest, independent units,
to prevent complexity and ensure precise data representation. Atomic projects allow for a more flexible
and accurate data comparison and combination between projects.
5.2.2. Adding Connections
Create just one connection and reuse it across projects by adding data scopes. This method optimizes data collection, minimizing redundancy and ensuring more efficient use of resources.
It is NOT recommended to create multiple connections, for instance, GitHub repos, as it
will increase the time to collect the data due to the storage of multiple copies of shared repos in the database.
The only exception is the webhooks: we must have 1 connection per project,
as this is the only way DevLake can accurately assign incidents to the corresponding project.
So, in total we will have only these connections:
- 1 connection for all GitHub
reposto collectpull requests - 1 connection to Jenkins to collect all
deployments - 1 connection to Jira to collect
incidents - 2 webhook connections to collect
incidents: 1 per eachprojectthat uses webhooks (it-legacy and it-new)
The step-by-step Configuration Guide shows how to both add connections and set scopes as described in the next chapter.
5.2.3. Setting Scopes
Now, add the connections to our projects and set the scope to them:
For payments project:
- add 1 scope to GitHub connection for p1...p10
reposto collect theirpull requests - add 1 scope to Jenkins for
deploymentsof p1...p10repos - add 1 scope to Jira to collect
incidents
For it-legacy project:
- add 1 scope to GitHub for
reposit-legacy-1, it-legacy-2, it-core-1 and it-core-2 to collect theirpull requests - add 1 scope to Jenkins for
deploymentsof it-legacy-1, it-legacy-2, it-core-1 and it-core-2repos - include the it-legacy webhook for collecting
incidents
For it-new project:
- add 1 scope to GitHub for
reposit-new-1, it-new-2, it-core-1 and it-core-2 to collect theirpull requests - add 1 scope to Jenkins for
deploymentsof it-new-1, it-new-2, it-core-1 and it-core-2repos - include the it-new webhook for collecting
incidents
5.2.4. Resulting Metrics
6. About Webhooks
Assigning a UNIQUE webhook to each project is critical. This ensures that the DevLake platform correctly associates the incoming data with the corresponding project through the webhook.
If you use the same webhook across multiple projects, the data sent by it will be replicated per each project that uses that webhook. More information available on the Webhook page
7. Troubleshooting
Please check out the Debugging DORA Issue Metrics to debug DORA dashboard.
If you still run into any problems, please check the Troubleshooting or create an issue